Doing this increases the size of the code substantially. The resulting image looks similar to the error diffusion shader, especially the version where it was clamped and interlaced with the original image. This one does not use the original image. It only uses 8 colours, but the way they are blended makes it appear as though there are more. It looks a bit like a gif.
NB: The low frame-rate in the bottom left is because this window isn't in focus, it is not a result of the shader.

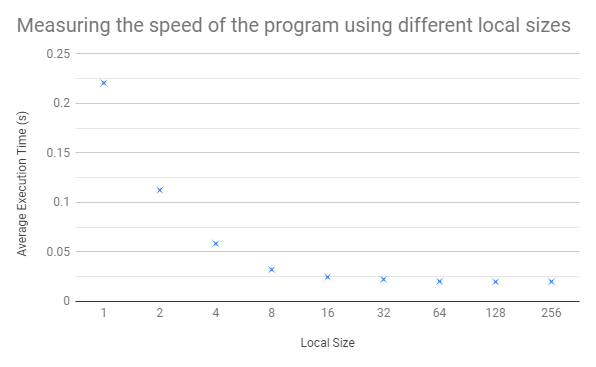
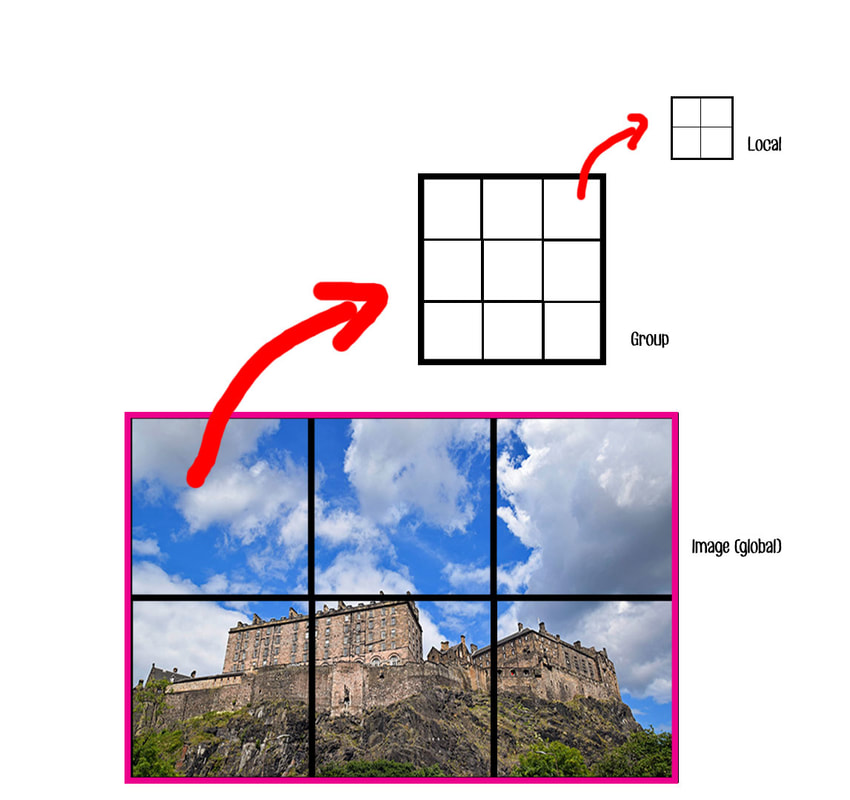


 RSS Feed
RSS Feed

