Background (Ethics)
There's no such thing as a protected image on the internet.
That said, there are ways to make image theft harder.
Here's my view on the ethics of the situation regarding LOLScans. We are a smallish group of volunteers (currently about 50 staff) who wish to share comics and manga from Asia with the rest of the world. We do not always get the author's consent, but we will always stop when asked, and we will never work on a project that is licensed in English. We get to share a story, the authors get some more publicity; and hype is built around an official release if there are plans for one.
We don't make money, it is not our intention. Our ad-revenue is $0 so far. We do accept donations, the proceeds of which go to paying for our web-server, and purchasing original comics to work on. I have also said in the past that I will never put ads on our reader.
So why do we want to protect our images if all we want to do is share them? There was a time when we did share them with an aggregator (a site that amasses comics from various groups) but after they changed their policy to let users upload licensed works, and stopped letting us recruit there, we cut our ties with them. The trouble then comes when people take our work without our permission (dodgy aggregators), these people do run ads on their site, they even block you from using the site if you have an ad-blocker. I have checked the traffic of some of these sites, through publicly available information, and can safely assume that they make a profit.
That is where the problem lies. They profit off our work. Our work has no monetary value. Ergo, they are profiting from the original artists. You may find my logic twisted and biased, but that is what I believe. So, I have taken it upon myself to stop them.
Abstract (Both sides of the same coin)
Stopping them is impossible, after all, our reader's purpose is to display images. What we can do is make things more difficult for them.
One way to discourage them a bit is to use watermarks, but watermarks are ugly, and they'll take your images whether you watermark them or not.
The fastest and most efficient way to rip images off a site is a control+s and your browser will do it for you. I should know, that's how we do it. There is a way to stop that. If you put the images in canvases, then remove the image tags from the page with a little JavaScript, they will no longer show up as sources. This can be gotten around by reloading the page with the developer tools open, a control+s still won't work but all the images will be laid bare. The best approach is to use blobs not URLs in conjunction with the canvases. That way you can't even see the images after you refresh the page with the developer tools open. However, you can still intercept this traffic as the page loads, and people have built tools to do that.
Side-note: Some reader applications don't do the above if you are browsing from a phone, sometimes you don't even have to trick them to think you are, you just have to prefix the URL with "m."
So all of that is not enough. Or you could skip it and do what I do... Our goal here is to make the thieves take screenshots - it will be their fastest method but it will still be tedious for them, plus if they don't have a good enough monitor the images won't be as good.
How do we do that? How do we annoy them so much that they stop trying to download the images and start taking screenshots? Scramble them of course!
Meat and Potatoes (and scrambled eggs)
A lot of reader applications do this. They often have their own proprietary approach. The most common one I found was to get rectangles from the image. Then display them in a seemingly random order in a grid. A naive (or data-saving) approach would be to use a grid whose regions were the same size and offset as the pixels they sampled from. Put to make things more complex, why not add that offset, make it more difficult to scramble? If you're confused by this concept, as I have not explained it well, or would like to see how that would look in practice, here is an image from Amazon's Comixology reader that uses that technique:
There's no such thing as a protected image on the internet.
That said, there are ways to make image theft harder.
Here's my view on the ethics of the situation regarding LOLScans. We are a smallish group of volunteers (currently about 50 staff) who wish to share comics and manga from Asia with the rest of the world. We do not always get the author's consent, but we will always stop when asked, and we will never work on a project that is licensed in English. We get to share a story, the authors get some more publicity; and hype is built around an official release if there are plans for one.
We don't make money, it is not our intention. Our ad-revenue is $0 so far. We do accept donations, the proceeds of which go to paying for our web-server, and purchasing original comics to work on. I have also said in the past that I will never put ads on our reader.
So why do we want to protect our images if all we want to do is share them? There was a time when we did share them with an aggregator (a site that amasses comics from various groups) but after they changed their policy to let users upload licensed works, and stopped letting us recruit there, we cut our ties with them. The trouble then comes when people take our work without our permission (dodgy aggregators), these people do run ads on their site, they even block you from using the site if you have an ad-blocker. I have checked the traffic of some of these sites, through publicly available information, and can safely assume that they make a profit.
That is where the problem lies. They profit off our work. Our work has no monetary value. Ergo, they are profiting from the original artists. You may find my logic twisted and biased, but that is what I believe. So, I have taken it upon myself to stop them.
Abstract (Both sides of the same coin)
Stopping them is impossible, after all, our reader's purpose is to display images. What we can do is make things more difficult for them.
One way to discourage them a bit is to use watermarks, but watermarks are ugly, and they'll take your images whether you watermark them or not.
The fastest and most efficient way to rip images off a site is a control+s and your browser will do it for you. I should know, that's how we do it. There is a way to stop that. If you put the images in canvases, then remove the image tags from the page with a little JavaScript, they will no longer show up as sources. This can be gotten around by reloading the page with the developer tools open, a control+s still won't work but all the images will be laid bare. The best approach is to use blobs not URLs in conjunction with the canvases. That way you can't even see the images after you refresh the page with the developer tools open. However, you can still intercept this traffic as the page loads, and people have built tools to do that.
Side-note: Some reader applications don't do the above if you are browsing from a phone, sometimes you don't even have to trick them to think you are, you just have to prefix the URL with "m."
So all of that is not enough. Or you could skip it and do what I do... Our goal here is to make the thieves take screenshots - it will be their fastest method but it will still be tedious for them, plus if they don't have a good enough monitor the images won't be as good.
How do we do that? How do we annoy them so much that they stop trying to download the images and start taking screenshots? Scramble them of course!
Meat and Potatoes (and scrambled eggs)
A lot of reader applications do this. They often have their own proprietary approach. The most common one I found was to get rectangles from the image. Then display them in a seemingly random order in a grid. A naive (or data-saving) approach would be to use a grid whose regions were the same size and offset as the pixels they sampled from. Put to make things more complex, why not add that offset, make it more difficult to scramble? If you're confused by this concept, as I have not explained it well, or would like to see how that would look in practice, here is an image from Amazon's Comixology reader that uses that technique:

Note how there are duplicated bits of text!
"SEEEK PALEEBLOOD TO
TRAANSCENDD THE HUUNT!"
This is quite good. I highly recommend this approach. Naturally, there are ways to unscramble it, and it is possible to automate such a process. More on that at the end.
So since we can see how the image ought to fit together, we might start trying to do that in an image editing program, record our actions once we know what we're doing, and repeat for the rest of the images. So as an added measure of security, it might be an idea to scramble your images differently - but know this: You should only put in as much effort as is required, remember, we are only trying to discourage people from unscrambling (and automation) so that they are forced to get the images in an "easier" way. You should also keep in mind that it is a lot easier to unscramble images - for displaying them - that have been scrambled the same way (until my approach, which I will talk about later).
My Approach
One of my earlier approaches to this problem was to do something similar to what Amazon did but a lot simpler - only swap the four quadrants of the image. Naturally this got "cracked / broken", so I added an extra layer of complexity (removing a depth, if this were cryptography). I made the images translucent. I would have made them fully transparent but there is a bug with canvases that does not preserve all the colour detail with fully transparent images. People got confused and started thinking it was a "filter". I would never use a filter, as that drops information from the image (that can't always be corrected properly). When I quizzed a friend about it, then revealed the solution they said they "never would have guessed that". Accidental Subterfuge!
The next step is to obscure the scrambling process. Every pixel must be moved to a seemingly random location! This is so that the thieves have no idea where to start when trying to unscramble the images. But how would one unscramble that? You would need a key. You could have a key in a file that only the server could read, but that's a little boring. Let's use another image.
This is where things get a bit complicated and hard to explain. We don't want the image to increase in size (dimensions, it's okay if it doesn't compress quite as well) so we have to use all available locations in the original image, and fill them with a different pixel from the image. The best way to do this is by swapping pixels.
I initially made a key was as big as the source image, whose pixels were unique, and whose pixels' values went from 0 (inclusive) and width * height (exclusive). The trouble with this is that such images take a really long time to generate, and while scrambling with it is effective, it also takes time. But how does the scrambling work with this method? As you may have guessed, each pixel's value acts as a pointer to an index within the source image to sample from. There is another problem with this method. Pixels can get swapped twice, especially those at the beginning. When they are swapped twice, they can't be unscrambled easily. A quick fix for this is to just not swap pixels that have already been swapped and use the original pixels at those locations. However, this makes the image look more like the original - we don't want any cohesion; confusion is the name of the game.
There is a similar approach to this that is much more efficient. Just have a one-dimensional key. Use that key on pairs of rows or columns and swap the pixels between them. This is a lot faster than the last approach. However, vertical lines (or horizontal ones, depending on your key's orientation) will persist as they are the same colour throughout. So it is kind of possible to get a general feel for what the image should be.
The next step to this is to do a double pass on the image with two keys. One vertical, one horizontal. Then to unscramble it, you have to do the same process in reverse, unlike the previous processes where you would just perform the same process again.
This is what I am doing now and the results are promising, here are the images from my single pass experiment:
"SEEEK PALEEBLOOD TO
TRAANSCENDD THE HUUNT!"
This is quite good. I highly recommend this approach. Naturally, there are ways to unscramble it, and it is possible to automate such a process. More on that at the end.
So since we can see how the image ought to fit together, we might start trying to do that in an image editing program, record our actions once we know what we're doing, and repeat for the rest of the images. So as an added measure of security, it might be an idea to scramble your images differently - but know this: You should only put in as much effort as is required, remember, we are only trying to discourage people from unscrambling (and automation) so that they are forced to get the images in an "easier" way. You should also keep in mind that it is a lot easier to unscramble images - for displaying them - that have been scrambled the same way (until my approach, which I will talk about later).
My Approach
One of my earlier approaches to this problem was to do something similar to what Amazon did but a lot simpler - only swap the four quadrants of the image. Naturally this got "cracked / broken", so I added an extra layer of complexity (removing a depth, if this were cryptography). I made the images translucent. I would have made them fully transparent but there is a bug with canvases that does not preserve all the colour detail with fully transparent images. People got confused and started thinking it was a "filter". I would never use a filter, as that drops information from the image (that can't always be corrected properly). When I quizzed a friend about it, then revealed the solution they said they "never would have guessed that". Accidental Subterfuge!
The next step is to obscure the scrambling process. Every pixel must be moved to a seemingly random location! This is so that the thieves have no idea where to start when trying to unscramble the images. But how would one unscramble that? You would need a key. You could have a key in a file that only the server could read, but that's a little boring. Let's use another image.
This is where things get a bit complicated and hard to explain. We don't want the image to increase in size (dimensions, it's okay if it doesn't compress quite as well) so we have to use all available locations in the original image, and fill them with a different pixel from the image. The best way to do this is by swapping pixels.
I initially made a key was as big as the source image, whose pixels were unique, and whose pixels' values went from 0 (inclusive) and width * height (exclusive). The trouble with this is that such images take a really long time to generate, and while scrambling with it is effective, it also takes time. But how does the scrambling work with this method? As you may have guessed, each pixel's value acts as a pointer to an index within the source image to sample from. There is another problem with this method. Pixels can get swapped twice, especially those at the beginning. When they are swapped twice, they can't be unscrambled easily. A quick fix for this is to just not swap pixels that have already been swapped and use the original pixels at those locations. However, this makes the image look more like the original - we don't want any cohesion; confusion is the name of the game.
There is a similar approach to this that is much more efficient. Just have a one-dimensional key. Use that key on pairs of rows or columns and swap the pixels between them. This is a lot faster than the last approach. However, vertical lines (or horizontal ones, depending on your key's orientation) will persist as they are the same colour throughout. So it is kind of possible to get a general feel for what the image should be.
The next step to this is to do a double pass on the image with two keys. One vertical, one horizontal. Then to unscramble it, you have to do the same process in reverse, unlike the previous processes where you would just perform the same process again.
This is what I am doing now and the results are promising, here are the images from my single pass experiment:
Here are the images from my double pass experiment, scrambled:
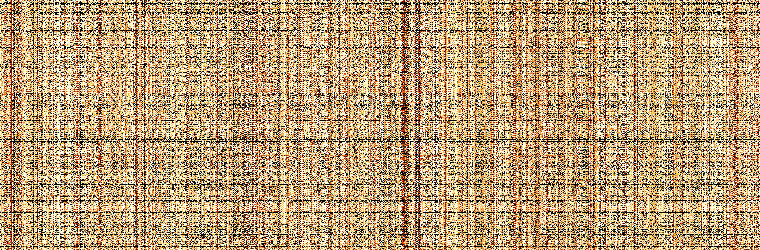
Unscrambled:

I like this approach because it is pretty much impossible to tell what the unscrambled image should look like from the scrambled image.
Of course, the pirates have access to the unscrambled image on the reader itself, but it is much harder to identify which image on the reader is which file they downloaded. It is harder to spot patterns too.
So where next?
If I were to use this, I would probably generate 2 keys for each image, and append them to the top and left sides of it, then scramble it using those keys, and unscramble it in much the same way. Of course, I would hide those pixels when I displayed it. There is some risk involved in doing that, the keys are quite easy to spot, and naturally they would be investigated. So I could have fixed keys hidden on the server somewhere. But having fixed keys comes with its own sets of problems, namely that each image would have to be the exact same size.
I would also reintroduce translucency.
But I will likely not do this, at least, not until I need to. It is currently more trouble than its worth, and I really have to consider the performance of unscrambling so many images at once in this way. There is, on top of that, an elephant in the room...
The common flaw
All these images have to be unscrambled on the client's end. You can't do it using PHP - you would just be giving them the images unscrambled. So you have to use JavaScript. There is a major problem with this, JavaScript is public. Anyone can see it. I obfuscate mine as anyone should, but that doesn't stop people from figuring it out. Once they've got that, they can just write their own application from it to unscramble it.
Fortunately for me, the pirates that I contend with haven't discovered this flaw. I will be forced to give up when they do. So let's keep screenshots appealing. We even have downloads for our projects with watermarks that are uploaded 3 days after our release on the reader (NB: not scrambled). These people are lazy, why wouldn't they wait 3 days for a slightly less high-quality version of the same product?
If they wanted, they could even become a VIP. VIPs get access to downloads on the same day as they are released in the reader. They also don't have watermarks.
I don't know how I'd feel about getting donations from a pirate. Food for thought.
Code
Since I'll likely not be using this method of scrambling, I might as well share the code. It is also incredibly unlikely that the pirates read my blog. It's in C# by the way, so that makes a change.
Of course, the pirates have access to the unscrambled image on the reader itself, but it is much harder to identify which image on the reader is which file they downloaded. It is harder to spot patterns too.
So where next?
If I were to use this, I would probably generate 2 keys for each image, and append them to the top and left sides of it, then scramble it using those keys, and unscramble it in much the same way. Of course, I would hide those pixels when I displayed it. There is some risk involved in doing that, the keys are quite easy to spot, and naturally they would be investigated. So I could have fixed keys hidden on the server somewhere. But having fixed keys comes with its own sets of problems, namely that each image would have to be the exact same size.
I would also reintroduce translucency.
But I will likely not do this, at least, not until I need to. It is currently more trouble than its worth, and I really have to consider the performance of unscrambling so many images at once in this way. There is, on top of that, an elephant in the room...
The common flaw
All these images have to be unscrambled on the client's end. You can't do it using PHP - you would just be giving them the images unscrambled. So you have to use JavaScript. There is a major problem with this, JavaScript is public. Anyone can see it. I obfuscate mine as anyone should, but that doesn't stop people from figuring it out. Once they've got that, they can just write their own application from it to unscramble it.
Fortunately for me, the pirates that I contend with haven't discovered this flaw. I will be forced to give up when they do. So let's keep screenshots appealing. We even have downloads for our projects with watermarks that are uploaded 3 days after our release on the reader (NB: not scrambled). These people are lazy, why wouldn't they wait 3 days for a slightly less high-quality version of the same product?
If they wanted, they could even become a VIP. VIPs get access to downloads on the same day as they are released in the reader. They also don't have watermarks.
I don't know how I'd feel about getting donations from a pirate. Food for thought.
Code
Since I'll likely not be using this method of scrambling, I might as well share the code. It is also incredibly unlikely that the pirates read my blog. It's in C# by the way, so that makes a change.
Bitmap keyV = new Bitmap("keyV.png"); // V = vertical
Bitmap keyH = new Bitmap("keyH.png"); // H = horizontal
Bitmap imgR = new Bitmap(imgName); // R = read
int w = imgR.Width;
int h = imgR.Height;
Bitmap imgW = new Bitmap(w, h); // W = write
// 1st Pass
for (int y = 0; y < h; y += 2)
{
for (int x = 0; x < w; x++)
{
int swapX = (0x00FFFF00 & keyH.GetPixel(x, 0).ToArgb()) >> 8; // Interpret wide horizontal key
Color swapColor = imgR.GetPixel(swapX, y + 1);
Color thisColor = imgR.GetPixel(x, y);
imgW.SetPixel(x, y, swapColor);
imgW.SetPixel(swapX, y + 1, thisColor);
}
}
Bitmap imgW2 = new Bitmap(w, h); // W2 = 2nd write
// 2nd Pass
for (int x = 0; x < w; x += 2)
{
for (int y = 0; y < h; y++)
{
int swapY = (0x00FF0000 & keyV.GetPixel(0, y).ToArgb()) >> 16; // Interpret short vertical key
Color swapColor = imgW.GetPixel(x + 1, swapY);
Color thisColor = imgW.GetPixel(x, y);
imgW2.SetPixel(x, y, swapColor);
imgW2.SetPixel(x + 1, swapY, thisColor);
}
}
// Save image and free memory
Some key things to note are the order that the axes are traversed in, and how the keys are interpreted.
Two write images may not be necessary but it makes it clearer. The second one was to fix a bug. This may not have fixed the bug, it may have been fixed by something else.
Two write images may not be necessary but it makes it clearer. The second one was to fix a bug. This may not have fixed the bug, it may have been fixed by something else.



 RSS Feed
RSS Feed

